
키-값 저장소 설계
키-값 저장소
- 키-값 저장소(key-value store)는 비 관계형(non-relational) 데이터베이스
- 저장되는 값은 고유 식별자(identifier)를 키로 가져야한다.
- 키와 값 연결관계를 "키-값" 쌍(pair)이라고 부른다.
키
- 키-값 쌍에서는 키는 유일해야 한다.
- 키를 통해서만 값에 접근할 수 있다.
- 키는 성능상의 이유로 키는 짧을 수록 좋다.
왜 키가 짧으면 좋지?(chat gpt 출처)
- 검색 속도 : 키를 기반으로 데이터를 검색하기 때문에 데이터 접근 방법에서는 더 효율적인 검색이 가능하다
- 메모리 사용 : 짧은 키는 크기도 작기 때문에 메모리 차지하는 비율도 적다.
- 코드 가독성 : 짧은 키는 이해하기 쉽고 유지보수가 편리해진다.
- 충돌 감소 : 충돌이 발생하면 검색 성능이 저하한다. 짧은 키는 충돌 가능성을 줄이는데 도움이 됩니다.
값
- 리스트, 객체일 수도 있으며 무엇이 값이든 상관없음
- 예
- 아마존 다이나모
- memcached
- 레디스
기능
- put(key, value) : 키-값 쌍을 저장소에 저장한다.
- get(key) : 인자로 주어진 키에 매달린 값을 꺼낸다.
문제 이해 및 설게 범위 확정
- 키-값 쌍의 크기는 10KB 이하이다.
- 큰 데이터를 저장할 수 있어야 한다.
- 높은 가용성을 제공해야 한다. 따라서 시스템은 설사 장애가 있더라도 빨리 응답해야 한다.
- 높은 규모 확장성을 제공해야 한다. 따라서 트래픽 양에 따라 자동적으로 서버 증설/삭제가 이루어져야 한다.
- 데이터 일관성 수준은 조정이 가능해야 한다.
- 응답 지연시간(latency)이 짧아야 한다.
단일 서버 키-값 저장소
- 키-값 쌍 전부 메모리에 해시 테이블로 저장
- 장점
- 빠른 속도를 보장
- 단점
- 모든 데이터를 메모리 안에 두는것이 불가능
- 개선책
- 데이터 암축(compression)
- 자주 쓰이는 데이터만 메모리에 두고 나머지는 디스크에 저장
분산 서버 키-값 저장소
- 키-값 쌍을 여러 서버에 분산하기 때문에 분산 해시 테이블이라고 부름
- CAP(Consistency, Availability, Partition Tolerance theorem) 이해 필요
CAP

- 데이터 일관성(Consistency)
- 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 한다.
- 모든 노드가 같은 순간에 같은 데이터를 볼 수 있음
- 가용성(Availability)
- 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
- 모든 요청이 성공 또는 실패결과를 반환할 수 있음
- 파티션 감내/분할내성(Partition Tolerance)
- 파티션은 두 노드 사이에 통신 장애가 발생하였음을 의미한다. 파티션 감내는 네트워크에 파티션이 생기더라도 시스테음 계속 동작하여야 한다는 것을 뜻함
- 메시지 전달이 실패하거나 시스템 일부가 망가져도 시스템이 계속 동작할 수 있음
- CP 시스템
- 일관성과 파티션 감내를 지원하는 키-값 저장소, 가용성을 희생한다.
- AP 시스템
- 가용성과 파티션 감내를 지원하는 키-값 저장소, 데이터 일관성을 희생한다.
- CA 시스템
- 일관성과 가용성을 지원하는 키-값 저장소, 파티션 감내는 지원하지 않음, 실세계에 CA 시스템은 존재하지 않음
이상적인 상태

- 3대의 복제(replica) 노드 n1, n2, n3에 데이터를 복제하여 보관하는 상황
- n1에 기록된 데이터는 자동적으로 n2와 n3에 복제
- 데이터 일관성과 가용성 만족
실세계의 분산 시스템

- 일관성과 가용성 중 하나를 선택 해야 함
- 일관성(CP 시스템)
- 3개의 노드의 데이터 불일치 문제를 피하기 위해 n1, n2 쓰기연산을 중단하므로 가용성이 깨짐
- 일관성이 깨진다면 상황이 해결할 때 까지 오류를 반환
- 가용성(AP 시스템)
- 과거 데이터를 반환할 위험이 있더라도 읽기 연산 허용
- n1, n2는 쓰기 연산 허용 하며 n3 문제가 해결되면 새 데이터를 n3에 전송
시스템 컴포넌트
- 키-값 저장소 구현 핵심 컴포넌트
- 데이터 파티션
- 데이터 다중화(replication)
- 일관성(consistency)
- 일관성 불일치 해소(incosistency resolution)
- 장애 처리
- 시스템 아키텍처 다이어그램
- 쓰기 경로(write path)
- 읽기 경로(read path)
데이터 파티션

- 데이터를 작은 파티션들로 분할한 다음 여러 대 서버에 저장
- 데이터를 파티션 단위로 나누는 기준
- 데이터를 여러 서버에 고르게 분산이 가능한가
- 노드가 추가되거나 삭제될 때 데이터의 이동을 최소화할 수 있는가
- 안정 해시를 사용하여 데이터 파티션을 적용하자.(5장 안정 해시)
- 안정 해시의 장점
- 규모 확장 자동화(automatic scaling)
- 시스템 부하에 따라 서버가 자동으로 추가되거나 삭제되도록 만들 수 있음
- 다양성(heterogeneity)
- 각 서버의 용량에 맞게 가상 노드의 수를 조정이 가능
- 고성능 서버는 더 많은 가상 노드를 갖도록 설정 가능
- 규모 확장 자동화(automatic scaling)
데이터 다중화

- 높은 가용성과 안정성을 확보하기 위해 N개의 서버에 비동기적으로 다중화(replication) 필요
- N은 서버 개수(튜닝 가능한 값)
- 키 기준 시계 방향으로 링을 순회하면서 만나는 첫 N개 서버에 데이터 사본을 보관
- 예
- key0 기준으로 s1, s2, s3에 저장
- 가상 노드를 사용하면 N개의 노드가 대응될 실제 물리 서버의 개수가 N보다 작아 질 수 있음
- 이러한 문제를 피하려면 같은 물리 서버를 중복 선택하지 않도록 해야함
- 같은 데이터 센터에 속한 노드도 물리적인 문제(정전,네트워크 이슈, 자연재해)로 이슈가 있을 수 있음
- 다른 센터의 서버에 보관하고 센터 끼리 고속 네트워크 연결 필요
데이터 일관성
- 여러 노드에 다중화된 데이터는 적절한 동기화 필요
- 정족수 합의(Quorum Consensus) 프로토콜을 사용하면 읽기/쓰기 연산 모두에 일관성 보장 가능
- 정족수란? 여러 사람의 합의로 운영되는 의사기관에서 의결을 하는데 필요한 최소한 참석자의 수

- N = 사본 개수
- W = 쓰기 연산에 대한 정족수, 쓰기 연산이 성공한 것으로 간주되려면 적어도 W의 서버로부터 쓰기 연산이 성공했다는 응답을 받아야함
- R = 읽기 연산에 대한 정족수, 읽기 연산이 성공한 것으로 간주되려면 적어도 R개의 서버로부터 응답을 받아야함
- 예
- W =1 일경우 다중화 s0, s1, s2 중 하나라도 쓰기 연산에 대한 응답이 중재자(coordinator)에게 받아야한다는 뜻
- s0에게 성공 응답을 받았을 경우 s1, s2는 응답을 기다릴 필요가 없음
- 중재자는 클라이언트와 노드 사이에서 프록시(proxy) 역할
- W, R 값이 작을 수록 빠른 응답 속도
- W,R 값이 클 수록 데이터 일관성은 향상되지만 느린 응답 속도
- W+R > N일 경우 강한 일관성
적절한 N, W, R 구하기
- R = 1, W = N : 빠른 읽기 연산에 최적화된 시스템
- R = N, W =1 : 빠른 쓰기에 연산에 최적화된 시스템
- W + R > N : 강한 일관성이 보장됨(보통 N = 3, W = R = 2)
- W + R <= N : 강한 일관성이 보장되지 않음
일관성 모델
- 강한 일관성(strong consistency)
- 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환한다.
- 약한 일관성(weak consistency)
- 읽기 연산은 가장 최근에 갱산된 결과를 반환하지 못할 수 있다.
- 최종 일관성(eventual consistency)
- 약한 일관성의 한 형태로, 갱신 결과가 결국에는 모든 사본에 반영(동기화)되는 모델
- 강한 일관성은 모든 사본에 현재 쓰기 연산의 결과가 반영될 때 까지 해당 데이터에 읽기/쓰기를 금지
- 고가용성 시스템에는 적합하지 않음
- 다이나모, 카산드라는 최종 일관성 모델을 사용
- 최종 일관성 모델은 쓰기 연산이 병렬적으로 발생할 경우 시스템에 저장된 값의 일관성이 깨질 수 있음
- 일관성이 깨지는 문제는 클라이언트측에서 해결이 가능
- 클라이언트측에서 데이터의 버전 정보를 활용해 일관성이 깨진 데이터를 읽지 않는 기법 활용
비 일관성 해소 기법 : 데이터 버저닝
- 데이터를 다중화시 가용성은 높음, 사본 간 일관성은 깨질 가능성 높음
- 버저닝(versioning), 벡터 시계(vector clock)로 문제 해결 가능한 기술
- 버저닝은 데이터를 변경할 때 마다 해당 데이터의 새로운 버전을 만드는 것
- 각 버전의 데이터는 변경 불가능(immutable)
데이터 일관성 깨지는 예시

- 서버1, 서버2은 get("name")으로 같은 결과인 john을 얻을 수 있음
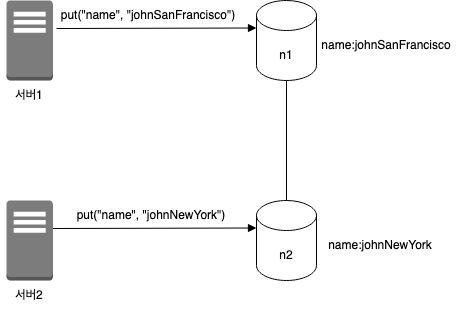
- 동시 연산으로 서버1은 name을 johnSanFrancisco, 서버2는 name을 johnNewYork으로 변경 요청
- 현재 충돌(conflict)하는 두 값을 가지게 됨. 그 각각을 버전 v1, v2라고 정함
- 이러한 문제를 해결하려면 버저닝 시스템이 필요하고 벡터 시계(vector clock)으로 사용할 수 있다?
벡터 시계(Vector Clock)
- 벡터 시계는 [서버, 버전]의 순서쌍을 데이터에 매단 것
- D([S1, v1], [S2,v2]...[Sn,vn] 표현
- D : 데이터
- Vi : 버전 카운터
- Si : 서버 번호
- [Si, Vi]가 있을 경우 Vi 증가
- 없을 경우 새 항목 [Si, 1] 새로 생성
벡터 시계 추상적 로직

- 클라이언트가 데이터 D1를 시스템에 기록, 서버x가 쓰기 연산 처리, 벡터 시계 D1([Sx,1])
- 타 클라이언트가 데이터 D1를 읽고 D2로 갱신 한뒤 기록, D2 -> D1에 대한 변경이므로 덮어쓰기, 서버 x가 쓰기 연산 처리, 벡터 시계 D2([Sx, 2])
- 타 클라이언트가 D2를 읽어 D3로 갱신한뒤 기록, 서버y가 쓰기 연산 처리, 벡터 시계 D3([Sx, 2],[Sy,1])
- 타 클라이언트가 D2를 읽어 D4로 갱신한뒤 기록, 서버z가 쓰기 연산 처리, 벡터 시계 D4([Sx, 2],[Sz,1])
- 타 클라이언트가 D3, D4를 읽어 데이터 간 충돌이 있다는걸 알아냄, D2를 sy, sz가 다른 값으로 변경했기 때문, 충돌을 해소한 뒤 서버에 기록, 백터 시계 D5([Sx, 3],[Sy,1],[Sz,1])
이전 버전 확인 방법
- 버전 Y에 포함된 모든 구성요소의 값이 X에 포함된 모든 구성요소 값보다 큰지만 보면 된다.
- 예
- D1([Sx,1])은 D2(Sx,2)보다 이전 버전
- 예
버전 충돌 확인 방법
- Y의 벡터 시계 구성요소 가운데 X의 벡터 시계 동일 서버 구성요소보다 작은 값을 갖는 것이 있는지 보면 된다.
- 예
- D([s0, 1], [s1, 2])와 D([s0, 2], [s1, 1])는 서로 충돌한다.
버전 충돌 및 해소 단점
- 충돌 감지 및 해소 로직이 클라이언트에 들어가야 하므로, 클라이언트 구현이 복잡
- [서버:버전]의 순서쌍 개수가 굉장히 빨리 늘어남
- 임계치(threshold)를 설정, 임계치 이상으로 길이 길어지면 오래된 순서쌍 제거
- 오래된 순서쌍 제거하면 버전 간 선후 관계를 파악하기 힘들고 충돌 해소 과정의 효율성이 낮아짐
- 그러나 AWS 다이나모에서는 문제가 발생한적이 없음 제거해도 될듯
장애 감지
- 두 대 이상의 서버가 한 서버가 장애 났다고 보고해야 발생했다고 간주
멀티캐스팅

- 모든 노드 사이에 멀티캐스팅(multicasting) 채널을 구축하는 것이 서버 장애를 감지하는 가장 쉬운 방법
- 단점
- 서버가 많으면 비효율적
가십 프로토콜(gossip protocol)

- 가십 프로토콜(gossip protocol) 같은 분산형 장애 감지(decentralized failure detection) 솔루션을 채택하는 편이 보다 효율적
- 동작 원리
- 각 노드는 멤버십 목록(membership list)를 유지
- 멤버십 목록은 각 멤버 ID와 그 박동 카운터(Heartbeat counter) 쌍의 목록
- 각 노드는 주기적으로 자신의 박동 카운터를 증가
- 각 노드는 무작위로 선정된 노드들에게 주기적으로 자기 박통 카운터 목록을 보냄
- 박동 카운터 목록을 받은 노드는 멤버십 목록을 최신 값으로 갱신
- 어떤 멤버의 박동 카운터 값이 지정된 시간 동안 갱신되지 않으면 해당 멤버는 장애(offline) 상태 인것으로 간주
- 예
- 노드 s0은 테이블과 같은 멤버십 목록을 가진 상태
- 노드 s0은 노드 s2(Member ID = 2)의 박동 카운터가 오랫동안 증가되지 않았다는 것을 발견
- 노드 s0은 노드 s2 포함하는 박동 카운터 목록을 무작위로 다른 노드에게 전달
- 노드 s2의 박동 카운터가 오랫동안 증가되지 않았음을 발견한 모든 노드는 해당 노드를 장애 노드로 표시
일시적 장애 처리

- 네트워크나 서버 문제로 장애 상태인 서버로 가는 요청은 다른 서버가 잠시 맡아 처리
- 그동안 발생한 변경사항은 해당 서버가 복구되었을 때 일괄 반영하여 데이터 일관성을 보존
- 이를 위해 임시로 쓰기 연산을 처리한 서버에는 그에 관한 단서를 남겨둔다.
- 장애 처리 방안을 단서 후 임시 위탁 기법이라고 부름
- 예)
- 장애 노드 s2에 대한 읽기 및 쓰기 연산은 일시적으로 노드 s3가 처리
- s2가 복구되면 s3은 갱신된 데이터를 s2로 인계
영구 장애 처리
- 반-엔트로피(anti-entropy) 프로토콜을 구현하여 사본들을 동기화하여 영구적 장애 처리할 예정
반-엔트로피 프로토콜
- 사본들을 비교하여 최신 버전으로 갱신하는 과정을 포함
- 사본 간의 일관성이 망가지는 상태를 탐지하고 전송 데이터의 양을 줄이기 위해서는 머클(Merkle) 트리 사용
- 각 노드에 보관된 값을 해쉬값으로 변경하여 서로 비교를 하여 다른 부분을 찾아내어 동기화하는 방식
- 다를 경우 내려가서 왼쪽부터 비교
- 해시 값을 모아둔 트리를 해시 트리라고도 불린다.
데이터 센터 장애 처리
- 데이터 센터 다중화
시스템 아키텍처 다이어그램

- 클라이언트는 키-값 저장소가 제공하는 API, 읽기연산 get(key), 쓰기 연산 put(key,value)와 통신
- 중재자(coordinator)는 클라이언트에게 키-값 저장소에 대한 프록시 역할하는 노드
- 노드는 안정 해시의 해시 링 위에 분포
- 노드를 자동으로 추가 또는 삭제할 수 잇도록 시스템은 분산
- 데이터는 여러 노드에 다중화
- 모든 노드가 같은 책임을 지므로 SPOF(Single Point of Failure) 존재하지 않음
노드 지원 기능
- 클라이언트 API
- 장애 감지
- 데이터 충돌 해소
- 장애 복구 메커니즘
- 다중화
- 저장소 엔진
- 등등...
쓰기 경로
- 쓰기 요청이 커밋 경로(commit log) 파일에 기록
- 데이터가 메모리 캐시에 기록
- 메모리 캐시에 가득차거나 임계치에 도달할 경우 데이터는 디스크에 있는 SSTable에 기록
- SSTable(Sorted-String Table) 키, 값 이 순서쌍이 정렬된 리스트 형태로 관리하는 테이블
읽기 경로
- 메모리 캐시에 있을 경우 바로 클라이언트에게 결과 반환
- 메모리 캐시에 없을 경우
- 디스크에 있는 볼륨 필터를 통해 어떠한 SSTable에 기록이 되어있는지 확인
- SSTable에 확인하여 클라이언트에게 결과 반환
요약
| 목표/문제 | 기술 |
| 대규모 데이터 저장 | 안정 해시를 사용해 서버들에 부하 분산 |
| 읽기 연산에 대한 높은 가용성 보장 | 데이터를 여러 데이터센터에 다중화 |
| 쓰기 연산에 대한 높은 가용성 보장 | 버저닝 및 벡터 시계를 사용한 충돌 해소 |
| 데이터 파티션 | 안정 해시 |
| 점진적 규모 확장성 | 안정 해시 |
| 다양성 | 안정 해시 |
| 조절 가능한 데이터 일관성 | 정족수 합의 |
| 일시적 장애 처리 | 느슨한 정족수 프로토콜과 단서 후 임시 위탁 |
| 영구적 장애 처리 | 머클 트리 |
| 데이터 센터 장애 대응 | 여러 데이터 센터에 걸친 데이터 다중화 |
출처
https://ebook-product.kyobobook.co.kr/dig/epd/ebook/E000003160871
가상 면접 사례로 배우는 대규모 시스템 설계 기초 | 알렉스 쉬 | 인사이트- 교보ebook
2020년 출간 이후 아마존베스트셀러! 아마존 컴퓨터네트워크응용 분야 베스트셀러 1위! 《가상 면접으로 배우는 대규모 시스템 설계 기초》는 16가지 실제 시스템 설계 면접 문제와 상세한 답안
ebook-product.kyobobook.co.kr
https://en.wikipedia.org/wiki/CAP_theorem
CAP theorem - Wikipedia
From Wikipedia, the free encyclopedia Need to sacrifice consistency or availability in the presence of network partitions In theoretical computer science, the CAP theorem, also named Brewer's theorem after computer scientist Eric Brewer, states that any di
en.wikipedia.org
'시스템 아키텍쳐 > 가상 면접 사례로 배우는 대규모 시스템 설계 기초' 카테고리의 다른 글
| 8장 URL 단축기 설계 (0) | 2023.08.02 |
|---|---|
| 7장 분산 시스템을 위한 유일ID 생성기 설계 (1) | 2023.08.02 |
| 5장 안정 해시 설계 (1) | 2023.07.26 |
| 4장 처리율 제한 장치의 설계 (1) | 2023.07.26 |
| 3장 시스템 설계 면접 공략법 (0) | 2023.07.24 |



